Guided tour¶
Foreword¶
This code has been developed chunk by chunk over more than 10 years now, starting with python2.3 or 4. Now it is a python3.6 software and, fortunately, my python skills have improved over the years. Problem is that several old parts, even after big efforts to correct the worst pieces, are still not very idiomatic.
Among these parts that need to be rewritten from scratch, the core is currently being developed as a separate library). One this is done, the old core will be completely removed.
Even if they’re not written as good as can be, the unit tests remain a precious tool to check nothing got broken when the core parts are written anew or debugged.
The documentation has been originately written using doxygen. Although it is an excellent documentation software, I have decided to move to Sphinx because it corresponds closer to python best practices. So, all doxygen-style comments will be turned into docstrings so mathmaker can use Sphinx to build the documentation. At the moment this work is just started, so the auto-generated Sphinx documentation is quite uncomplete now.
Before working further on bringing new features, there’s a need for more annoying work, to turn ugly old parts into the right pythonic idioms. That’s why at places you’ll see that this or this other module is deprecated and should be “reduced”, or rewritten. Refer to the issues and projects on github.
The issue¶
It is utmost important to understand that mathmaker is not a software intended to compute mathematical stuff, but to display it. For instance, resolving a first-degree equation is not in itself a goal of mathmaker, because other softwares do that already (and we don’t even need any software to do it). The true goal of mathmaker is to determine and display the steps of this resolution. Whenever possible, mathmaker will try to mimic the pupils’ way of doing things.
For instance, it won’t automatically simplify a fraction to make it irreducible in one step, but will try to reproduce the steps that pupils usually need to simplify the fraction. So the GCD is only used to check when the fraction is irreducible and for the cases where there’s no other choice, but not as the mean to simplify a fraction directly (not before pupils learn how to use it, at least).
Another example is the need of mathmaker to control the displaying of decimal and integer numbers perfectly. Of course, most of the time, it doesn’t matter if a computer tells that 5.2×5.2 = 27.040000000000003 or 3.9×3.9 = 15.209999999999999 because everyone knows that the correct results are 27.04 and 15.21 and because the difference is not so important, so in many situations, this precision will be sufficient. But, mathmaker can’t display to pupils that the result of 5.2×5.2 is 27.040000000000003. (This problem is addressed by the use of Decimal that is extended by mathmakerlib)
Also, the human rules we use to write maths are full of exceptions and odd details we don’t notice usually because we’re familiar to them. We would never write
+2x² + 1x - 1(+5 - 1x)
but instead
2x² + x - (5 - x)
There are many conventions in the human way to write maths and many exceptions.
These are the reasons why the old core is quite complex: re-create these writing rules and habits on a computer and let the result be readable by pupils is not an easy thing.
Workflow¶
Mathmaker creates Sheets of maths Exercises.
Each Exercise contains Questions.
Each Question uses objects from the core, that embbed enough information to compute and write the text of the Question and also the answer.
The main executable (entry_point() in mathmaker/cli.py) performs following steps:
- Load the default settings from configuration files.
- Setup the main logger.
- Check that the correct dependencies are installed.
- Parse the command-line arguments, updates the settings accordingly.
- Install the language and setup shared objects, like the database connection.
- If the main directive is
list, it just write the directives list to stdout - Otherwise, it checks that the directive matches a known sheet (either a yaml or xml file or a sheet’s name that mathmaker provides) and writes the result to the output (
stdoutor a file) (xml will be dropped in 0.7.5)
The directories¶
Directories that are relevant to git, at the root:
.
├── docs
├── mathmaker
├── tests
└── toolbox
- The usual
docs/andtests/directories mathmaker/contains the actual python source codetoolbox/contains several standalone scripts that are useful for developers only (not users)- Several usual files (
.flake8etc.) outfiles/(not listed here, because it is not relevant to git) is where the garbage is put (figures created when testing, etc.). Sometimes it is useful to remove all garbage files it contains.
mathmaker/’s content:
$ tree -d -L 1 mathmaker -I __pycache__
mathmaker
├── data
├── lib
├── locale
└── settings
data/is where the database is stored, but also yaml files containing additional wordings, translations etc.lib/contains all useful classes and submodules (see below).locale/contains all translation files.settings/contains the functions dedicated to setup the settings and also the default settings files themselves.
lib/’s content:
$ tree -d -L 3 mathmaker/lib -I __pycache__
mathmaker/lib
├── constants
├── core
├── document
│ ├── content
│ │ ├── algebra
│ │ ├── calculation
│ │ ├── geometry
│ │ └── ... (maybe some others in the future)
│ └── frames
├── machine
├── old_style_sheet
│ └── exercise
│ └── question
└── tools
constants/contains several constants (butpythagorean.pymust be replaced by requests to the database)core/contains all mathematical objects, numeric or geometric; oncemathmakerlibcontains all its features, it will be removeddocument/contains the frames for sheets, exercises in questions, underdocument/frames/, and the questions’ content, underdocument/content/.machine/contains the “typewriter”old_style_sheet/contains all old style sheets, exercices and questions. All of this is obsolete (will be replaced by generic objects that take their data from yaml files and created by the objects defined indocument/frames/)tools/contains collections of useful functions nad objects__init__.pycontains various functionsdatabase.pycontains all functions required to interact with mathmaker’s databaseframeworks.pycontains a collection of useful functions to handle the collection of yaml sheet filesignition.pycontains several functions called at startupmaths.pycontains some extra mathematical functionswording.pycontains a collection of useful functions to handle wordingsxml.pycontains a collection of useful functions to handle the xml files (obsolete, will disappear in 0.7.5)
shared.pycontains objects and variables that need to be shared (except settings), like the database connection
Overview of the main classes¶
A Machine is like a typewriter: it turns all printable objects (Sheets, and everything they contain) into LaTeX. It knows how to turn a mathematical expression in LaTeX format. It knows how to draw figures from the geometrical objects (using eukleides).
The Sheet objects given to a Machine contain guidelines for the Machine: the layout of the Sheet and what Exercises it contains.
The Exercise objects contain Questions and also layout informations that might be specific to the exercise (for instance, display the equations’ resolutions in two columns).
The Question objects contain the mathematical objects from the core and uses them to compute texts and answers. The real content is in lib/document/content/*/*.py. The appropriate module is used by the Question object (defined in lib/document/frames/question.py) to create the question’s mathematical objects, wording and answer.
The objects from the core are all different kinds of mathematical objects, like Sums, Products, Equations or Triangles, Tables… For instance, a Question about Pythagora’s theorem would embed a RightTriangle (which itself embeds information on its sides, vertices, angles; and enough methods to create a picture of it) but also fields telling if the figure should be drawn in the Question’s text or if only a description of the figure should be given; if the hypotenuse should be calculated or another side; if the result should be a rounded decimal and how precise it should be etc.
When a new Sheet is created, all objects it contains are created randomly, following some rules, though, to avoid completely random uninteresting results.
More details about the core objects a little bit below, in the paragraph about The core.
Start working on mathmaker¶
Short version¶
Warning
Git and python>=3.6 are required.
Install dependencies:¶
Ubuntu 18.04+
$ sudo apt-get install eukleides libxml2-utils gettext texlive-full
Note
If you work on an older Ubuntu version, then most probably the binary package is outdated (should be >= 2017), and then instead, install TeXLive over the internet, like described on the official website. Do not forget to setup the fonts for lualatex.
Manjaro
$ sudo pacman -S python-pip texlive-most libxml2 python-lxml gettext $ yaourt -S eukleides
FreeBSD
$ sudo pkg install python36 py36-sqlite3 gettext eukleides libxml2 $ rehash $ python3.6 -m ensurepip
Note
FreeBSD users: in 2018 (mathmaker 0.7.3), the binary version of TeXLive is outdated (2015) and it is, again, necessary to install texlive directly using texlive instructions. Do not forget to setup the fonts for lualatex if you intend to use them (as described in the same page).
Note
You should check the eukleides install fix for FreeBSD
Install mathmaker in dev mode:¶
To install mathmaker in dev mode in a venv, get to the directory where you want to work:
Linux
$ python3 -m venv dev0 $ source dev0/bin/activate (dev0) $ pip3 install pytest tox flake8 pydocstyle sphinx sphinx-autodoc-annotation sphinx-rtd-theme (dev0) $ mkdir mathmaker (dev0) $ cd mathmaker/ (dev0) $ git clone https://github.com/nicolashainaux/mathmaker.git (dev0) $ python3 setup.py develop
FreeBSD
$ python3 -m venv dev0 $ source dev0/bin/activate.csh [dev0] $ sudo pip3 install pytest tox flake8 pydocstyle sphinx sphinx-autodoc-annotation sphinx-rtd-theme [dev0] $ mkdir mathmaker [dev0] $ cd mathmaker/ [dev0] $ git clone https://github.com/nicolashainaux/mathmaker.git [dev0] $ python3 setup.py develop
Try it¶
Get to an empty directory and:
(dev0) $ mathmaker 06_orange_exam > out.tex 2> stderr.log && lualatex out.tex
You can check out.pdf with the pdf viewer you like.
To run the auxiliary tools:
(dev0) $ cd path/to/mathmaker/toolbox/
(dev0) $ ./build_db.py
(dev0) $ ./update_pot_files
Most of the tests are stored under tests/. Some others are doctests. Any new test or doctest will be added automatically to the tests run by pytest.
Run the tests:
(dev0) $ pytest -x -vv -r w tests/
Edit the settings:
(dev0) $ cd path/to/mathmaker/settings/
(dev0) $ mkdir dev/
(dev0) $ cp default/*.yaml dev/
In dev/logging.yaml you can set the __main__ logger to INFO (take care to define log rotation for /var/log/mathmaker). Set the dbg logger to DEBUG.
Each debugging logger can be enabled/disabled individually in debug_conf.yaml (by setting it to DEBUG or INFO).
See Loggers: main, daemon, debugging, output watcher for more details on how to setup new loggers (and debugging loggers).
You can override settings in dev/user_config.yaml to your liking.
Before starting, you should read at least the Auxiliary tools and Writing rules sections. It is certainly worth also to have a look at Advanced features.
Hope you’ll enjoy working on mathmaker!
Detailed version¶
Dev environment¶
Note
git and python>=3.6 are mandatory for mathmaker development
Install external dependencies¶
You’ll need to install the same dependencies as users do (see Install), plus gettext.
Get mathmaker’s source code from github repo¶
In the folder of your choice:
$ git clone https://github.com/nicolashainaux/mathmaker.git
Setup a python virtual environment¶
It is strongly advised to install mathmaker in develop mode inside of a python virtual environment. This allows to install the required libraries without conflicting with other projects or python software on the same computer. Just get to the directory of your choice, and to create a virtual environment named dev0, you type:
$ python3 -m venv dev0
From there, you can activate it:
on Linux:
$ source dev0/bin/activate
on FreeBSD:
$ source dev0/bin/activate.csh
Install mathmaker¶
Once your virtual environment is activated, go to mathmaker’s root:
(dev0) $ cd path/to/mathmaker/
You should see something like:
(dev0) $ ls
CHANGELOG.rst docs LICENSE MANIFEST.in mathmaker README.md README.rst requirements.txt setup.py tests tools tox.ini
There you can install mathmaker in developer mode:
(dev0) $ python3 setup.py develop
It’s possible to clean the project’s main directory:
(dev0) $ python3 setup.py clean
Run mathmaker and tools¶
From now on, it is possible to run mathmaker from your virtual environment. As mathmaker is installed in developer mode, any change in the source files will be effective when running mathmaker. Go to a directory where you can leave temporary files (old sheets with pictures will produce .eps files, and LaTeX compilation produces also a bunch of auxiliary files), and test it:
(dev0) $ cd path/to/garbage/directory/
(dev0) $ mathmaker 06_orange_exam > out.tex 2> stderr.log && lualatex out.tex
You can check out.pdf with the pdf viewer you like.
You can also run the tools from the toolbox. Somewhat below, more informations about the Auxiliary tools.
Once you’re done working with mathmaker, you can deactivate the virtual environment:
(dev0) $ deactivate
$
Note
It is not recommanded to run mathmaker outside the virtual environment. For information, the possible command is cd path/to/mathmaker/ && python3 -m mathmaker.cli. Not sure it still works, and would require to have the python dependencies installed too, on the main system (outside the virtual environment) and maybe also to have correctly set and exported $PYTHONPATH.
Other dependencies¶
Linters¶
It is recommended to install linters for PEP 8 and PEP 257 (see Writing rules):
(dev0) $ pip3 install flake8
(dev0) $ pip3 install pydocstyle
Note
PEP 257 is not yet really applied… but PEP 8 is!
Test dependencies¶
In addition you should install at least pytest, and maybe tox if you intend to include tox tests in mathmaker:
(dev0) $ pip3 install pytest
(dev0) $ pip3 install tox
Below is more information about testing.
Documentation dependencies¶
You’ll need to install these dependencies in the virtual environment:
(dev0) $ pip3 install sphinx sphinx-rtd-theme
sphinx-rtd-theme is the theme used for mathmaker’s documentation. It’s the readthedocs theme.
Note
sphinx-autodoc-annotation makes writing docstrings lighter when using python3 annotations.
Below is more information about documentation.
Dev settings¶
You should make a copy of the default configuration files:
(dev0) $ cd path/to/mathmaker/settings/
(dev0) $ mkdir dev/
(dev0) $ cp default/*.yaml dev/
Then you can edit the files in mathmaker/settings/dev/ to your liking. Any value redefined there will override all other settings (except the options from the command line).
In logging.yaml the loggers part is interesting. I usually set the __main__ logger to INFO (this way, informations about starting and stopping mathmaker are recorded to /var/log/mathmaker, take care to define the log rotation if you do so) and the dbg logger to DEBUG. This second setting is important because it will allow to enable debugging loggers in debug_conf.yaml.
debug_conf.yaml allows to trigger each debugging logger individually by setting it to DEBUG instead of INFO.
And in user_config.yaml it is especially nice to define an output directory where all garbage files will be stored, but also to set the language, the font etc.
For instance, my settings/dev/user_config.yaml contains this:
# SOFTWARE'S CONFIGURATION FILE
PATHS:
OUTPUT_DIR: dev/mathmaker/poubelle/
LOCALES:
LANGUAGE: fr_FR
CURRENCY: euro
LATEX:
FONT: Ubuntu
ROUND_LETTERS_IN_MATH_EXPR: True
DOCUMENT:
QUESTION_NUMBERING_TEMPLATE_SLIDESHOWS: "n°{n}"
See Settings to learn more about the way settings are handled by mathmaker.
Testing¶
Run the tests¶
The testing suite is run by pytest this way:
(dev0) $ pytest
or this way:
(dev0) $ python3 setup.py test
Where do they live?¶
Most of the tests belong to tests/. Any function whose name starts with test_ written in any python file whose name also starts with test_ or ends with _test (and stored somewhere under tests/) and will be automatically added to the tests run by pytest.
Some more tests are written as doctests (see also pytest documentation about doctests) in the docstrings of the functions. It’s possible to add doctests, especially for simple functions (sometimes it is redundant with the tests from tests/, but this is not a serious problem). The configuration for tests is so that any new doctest will be automatically added to the tests run by pytest.
Tox¶
Still needs to be setup for mathmaker. To test mathmaker against different versions of python, we should be able to run tox this way:
(dev0) $ tox
or this way:
(dev0) $ python3 setup.py tox
Be sure you have different versions of python installed correctly on your computer before starting this. The missing versions will be skipped anyway. Note that it is not a purpose of mathmaker to run under a lot of python versions (several python3 versions are OK, but no support for python2.7 is planned and that would be a waste of time since the end of development of python 2.7 is planned for 2020).
Loggers: main, daemon, debugging, output watcher¶
See Dev settings to know how to use the settings files and enable or disable logging and debugging.
Main logger¶
__main__ is intended to be used for messages relating to mathmaker general working. In particular, it should be used to log any error that forces mathmaker to stop, before it stops.
In order to use this __main__ logger, you can write this at the start of any function (assuming you have imported settings at the top of the file):
log = settings.mainlogger
And then inside this function:
log.error("message")
(or log.warning("message") or log.critical("message") depending on the severity level).
If an Exception led to stop mathmaker, then the message should include its Traceback (if you notice this is not the case somewhere, you can modify this and make a pull request). For instance in cli.py:
try:
shared.machine.write_out(str(sh))
except Exception:
log.error("An exception occured during the creation of the sheet.",
exc_info=True)
shared.db.close()
sys.exit(1)
Daemon logger¶
This logger is intended to be used by the daemon script. Works the same way as the main logger.
Debugging logger¶
dbg is the logger dedicated to debugging and ready to use. No need to write sys.stderr.write(msg) anywhere.
If there’s no logger object in the function you want to print debugging messages, you can create one this way:
Add the matching entry in
debug_conf.yaml(both thesettings/default/andsettings/dev/versions, but set toINFOin thesettings/default/version). For short modules, you can add only one level, and for modules containing lots of functions of classes, two levels should be added, like the example of the extract below:dbg: db: INFO wording: merge_nb_unit_pairs: INFO setup_wording_format_of: INFO insert_nonbreaking_spaces: INFO class_or_module_name: fct: DEBUG
Import the settings at the top of the file, if it’s not done yet:
from mathmaker import settings
Create the logger at the start of the function (i.e. locally):
def fct(): log = settings.dbg_logger.getChild('class_or_module_name.fct')
Then where you need it, inside
fct, write messages this way:log.debug("the message you like")
Later when you need to disable this logger, you just set it to INFO instead of DEBUG in settings/dev/debug_conf.yaml. See Dev settings for information on these files.
(Will be obsolete once the core is replaced by mathmakerlib) A summary of the conventions used to represent the different core objects (i.e. what their __repr__() returns):

Output Watcher logger¶
This is another debugging logger. It can be used to check wether output is as expected, in order to detect bugs that do not crash mathmaker. Works the same way as the main logger. The log messages are sent to another facility (local4), in order to be recorded independently.
System log configuration¶
Warning
Informations of this subsubsection are certainly outdated since most Linux systems switch to systemd, what makes the use of rsyslog more difficult, unfortunately.See issue #61.
Systems using rsyslog¶
The communication with rsyslog goes through a local Unix socket (no need to load rsyslog TCP or UDP modules).
Note
The default socket is /dev/log for Linux systems, and /var/run/log for FreeBSD. These values are defined in the logging*.yaml settings files.
rsyslog may be already enabled and running by default (Ubuntu) or you can install, enable and start it (in Manjaro, # systemctl enable rsyslog and # systemctl start rsyslog).
Ensure /etc/rsyslog.conf contains these lines:
$ModLoad imuxsock
$IncludeConfig /etc/rsyslog.d/*.conf
Then create (if not created yet) a ‘local’ configuration file, like: /etc/rsyslog.d/40-local.conf and put (or add) in it:
# Local user rules for rsyslog.
#
#
local4.* /var/log/mathmaker_output.log
local5.* /var/log/mathmaker.log
local6.* /var/log/mathmakerd.log
Then save it and restart:
- in Ubuntu:
# service rsyslog restart - in Manjaro:
# systemctl restart rsyslog
Warning
Do not create /var/log/mathmaker.log yourself with the wrong rights, otherwise nothing will be logged.
To format the messages in a nicer way, it’s possible to add this in /etc/rsyslog.conf:
$template MathmakerTpl,"%$now% %timegenerated:12:23:date-rfc3339% %syslogtag%%msg%\n"
and then, modify /etc/rsyslog.d/40-local.conf like:
local4.* /var/log/mathmaker_output.log;MathmakerTpl
local5.* /var/log/mathmaker.log;MathmakerTpl
local6.* /var/log/mathmakerd.log;MathmakerTpl
Tools to check everything’s fine: after having restarted rsyslog, enable some more informations output:
# export RSYSLOG_DEBUGLOG="/var/log/myrsyslogd.log"
# export RSYSLOG_DEBUG="Debug"
and running the configuration validation:
# rsyslogd -N2 | grep "mathmaker"
should show something like (errorless):
rsyslogd: version 7.4.4, config validation run (level 2), master config /etc/rsyslog.conf
2564.153590773:7f559632b780: ACTION 0x2123160 [builtin:omfile:/var/log/mathmaker.log;MathmakerTpl]
2564.154126386:7f559632b780: ACTION 0x2123990 [builtin:omfile:/var/log/mathmakerd.log;MathmakerTpl]
2564.158461309:7f559632b780: ACTION 0x2123160 [builtin:omfile:/var/log/mathmaker.log;MathmakerTpl]
2564.158729012:7f559632b780: ACTION 0x2123990 [builtin:omfile:/var/log/mathmakerd.log;MathmakerTpl]
rsyslogd: End of config validation run. Bye.
Once you’ve checked this works as expected, do not forget to configure your log rotation.
Note
mathmaker does not support systemd journalisation (the default one in Manjaro). You may have to setup systemd too (enable ForwardToSyslog in its conf file) in order to get rsyslog recording messages. Also you may need is to add $ModLoad imjournal in /etc/rsyslog.conf and to create the file /var/spool/rsyslog. For a better setup, see https://www.freedesktop.org/wiki/Software/systemd/syslog/. A workaround to prevent duplicate messages could be to discard the unwanted ones, like described here: http://www.rsyslog.com/discarding-unwanted-messages/.
Documentation¶
Current state¶
As stated in the Foreword, the documentation is being turned from doxygen to Sphinx, so there are missing parts.
Any new public function or module has to be documented as described in PEP 257. A part of the boring but necessary work to do is to add these docstrings (or turn the doxygen-style comments to docstrings), but do not rush into it too quickly as many parts should be rewritten, most of the missing or doxygen-style comments will match methods that will disappear.
The doxygen documentation for version 0.6 is here. The core parts are still correct, so far, but the core is being rewritten as a separate library.
Format¶
This documentation is written in ReStructured Text format.
There are no newlines inside paragraphs. Set your editor to soft wrap lines or not, to your liking.
Make html¶
To produce the html documentation:
(dev0) mathmaker [dev] $ cd docs/
(dev0) mathmaker/docs [dev] $ make html
If modules have changed (new ones, deleted ones), it is necessary to rebuild the autogenerated index:
(dev0) mathmaker/docs [dev] $ sphinx-apidoc -f -o . ../mathmaker
Auxiliary tools¶
Several standalone scripts live in the toolbox/ directory under root. They can be useful for several tasks that automate the handling of data.
build_db.pyrebuilds the database from scratch, updating its data from several sources (some *.yaml files, *.po files etc.). This tool greatly needs to be rewritten! And once the database is smaller, it should be included in the main code and used to generate the database that will be shipped).build_index.pymust be run when a new sheet is to be “registered” (or removed)update_pot_files, a shell script making use ofxgettextand of the scriptsmerge_py_updates_to_main_pot_file,merge_yaml_updates_to_pot_fileandmerge_xml_updates_to_pot_file(this last one will be removed in 0.7.2). Runupdate_pot_filesto updatelocale/mathmaker.potwhen new strings to translate have been added to python code (i.e. inside a call to_()) or new entries have been added to any yaml or xml (xml files will be turned to yaml files in 0.7.2) file frommathmaker/data(only entries matching a number of identifiers are taken into account, see DEFAULT_KEYWORDS in the source code to know which ones exactly).
import_msgstr and retrieve_po_entries are useful on some rare occasions. See their docstrings for more explanations. They both have a --help option.
pythagorean_triples_generator shouldn’t be of any use any more (later on maybe a part of its code will be incorporated to build_db.py, that’s why it’s still around here)
Writing rules¶
It is necessary to write the cleanest code possible. It has not been the case in the past, but the old code is updated chunk by chunk and any new code portion must follow python’s best practices, to avoid adding to the mess, and so, must:
- Use idioms (to learn some, it is recommended to read Jeff Knupp’s Writing Idiomatic Python)
- Conform to the PEP 8 – Style Guide for Python
- Conform to the PEP 257 – Docstring Conventions
And of course, all the code is written in english.
As to PEP 8, mathmaker ‘s code being free from errors, the best is to use a linter, like flake8. They also exist as plugins to various text editors or IDE (see Atom packages for instance). Three error codes are ignored (see .flake8):
E129 because it is triggered anytime a comment is used to separate a multiline conditional of an
ifstatement from its nested suite. A choice has been made to wrap multiline conditions in()and realize the separation with next indented block using a# __comment (or any other comment if it’s necessary) and this complies with PEP 8 (second option here):Acceptable options in this situation include, but are not limited to:
# No extra indentation. if (this_is_one_thing and that_is_another_thing): do_something() # Add a comment, which will provide some distinction in editors # supporting syntax highlighting. if (this_is_one_thing and that_is_another_thing): # Since both conditions are true, we can frobnicate. do_something()
W503 because PEP 8 does not compel to break before binary operators (the choice of breaking after binary operators has been done).
E704 because on some occasions it is OK to put several short statements on one line in the case of
def. It is the case in several test files using lines likedef v0(): return Value(4)
Other choices are:
- A standard maximum line length of 79
- Declare
_as builtin, otherwise all calls to_()(i.e. the translation function installed by gettext) would trigger flake8’s error F821 (undefined name). - No complexity check. This might change in the future, but the algorithms in the core are complex. It’ll be a lot of work to make them more simple (this will be done while rewriting the core as mathmakerlib and also using DataSource and other new objects to better handle sheets, exercises, questions and data/numbers sources).
- Name modules, functions, instances, and other variables in lower case, whenever possible using a single
wordbut if necessary, usingseveral_words_separated_with_underscores. - Name classes in CapitalizedWords, like:
SuchAWonderfullClass(don’t use mixedCase, likewrongCapitalizedClass). - All
importstatements must be at the top of any module. It must be avoided to addfrom ... import ...at the top of some functions, but sometimes it’s necessary. A solution to avoid this is always preferred. - All text files (including program code) are encoded in UTF-8.
As to PEP 257, this is also a good idea to use a linter, but lots of documentation being written as doxygen comments, the linter will detect a lot of missing docstrings. Just be sure the part you intend to push does not introduce new PEP 257 errors (their number must decrease with time, never increase).
The text of any docstring is marked up with reStructuredText.
The module mathmaker.lib.tools.wording can be considered as a reference on how to write correct docstrings. As an example, the code of two functions is reproduced here.
Note
The use of python3’s annotations and sphinx-autodoc-annotation would automatically add the types (including return type) to the generated documentation. As sphinx-autodoc-annotation’s bug is corrected, the :type ...: ... and :rtype: ... lines may be removed (but sphinx-autodoc-annotation is not setup anymore in mathmaker… so have to set it up again).
def cut_off_hint_from(sentence: str) -> tuple:
"""
Return the sentence and the possible hint separated.
Only one hint will be taken into account.
:param sentence: the sentence to inspect
:type sentence: str
:rtype: tuple
:Examples:
>>> cut_off_hint_from("This sentence has no hint.")
('This sentence has no hint.', '')
>>> cut_off_hint_from("This sentence has a hint: |hint:length_unit|")
('This sentence has a hint:', 'length_unit')
>>> cut_off_hint_from("Malformed hint:|hint:length_unit|")
('Malformed hint:|hint:length_unit|', '')
>>> cut_off_hint_from("Malformed hint: |hint0:length_unit|")
('Malformed hint: |hint0:length_unit|', '')
>>> cut_off_hint_from("Two hints: |hint:unit| |hint:something_else|")
('Two hints: |hint:unit|', 'something_else')
"""
last_word = sentence.split()[-1:][0]
hint_block = ""
if (is_wrapped(last_word, braces='||')
and last_word[1:-1].startswith('hint:')):
# __
hint_block = last_word
if len(hint_block):
new_s = " ".join(w for w in sentence.split() if w != hint_block)
hint = hint_block[1:-1].split(sep=':')[1]
return (new_s, hint)
else:
return (sentence, "")
def merge_nb_unit_pairs(arg: object):
r"""
Merge all occurences of {nbN} {\*_unit} in arg.wording into {nbN\_\*_unit}.
In the same time, the matching attribute arg.nbN\_\*_unit is set with
Value(nbN, unit=Unit(arg.\*_unit)).into_str(display_SI_unit=True)
(the possible exponent is taken into account too).
:param arg: the object whose attribute wording will be processed. It must
have a wording attribute as well as nbN and \*_unit attributes.
:type arg: object
:rtype: None
:Example:
>>> class Object(object): pass
...
>>> arg = Object()
>>> arg.wording = 'I have {nb1} {capacity_unit} of water.'
>>> arg.nb1 = 2
>>> arg.capacity_unit = 'L'
>>> merge_nb_unit_pairs(arg)
>>> arg.wording
'I have {nb1_capacity_unit} of water.'
>>> arg.nb1_capacity_unit
'\\SI{2}{L}'
"""
Atom packages¶
This paragraph lists useful packages for atom users (visit the links to have full install and setup informations):
flake8linter provider: linter-flake8 (Note: you should let the settings as is, except for the “Project config file” entry where you can write “.flake8” to usemathmakerproject’s settings.)pydocstylelinter provider: linter-pydocstyle- python3’s highlighter: MagicPython (MagicPython is able to highlight correctly python3’s annotations. You’ll have to disable the language-python core package.)
- To edit rst documentation: language-restructuredtext and rst-preview-pandoc
A deeper look in the source code¶
Settings¶
Everything happens in mathmaker/settings/__init__.py (it would be better to have everything happening rather in something like mathmaker/settings/settings.py, so this will most certainly change).
This module is imported by the main script at start, that run its init() function. After that, any subsequent from mathmaker import settings statement will make settings.* available.
The values shared as settings.* are: the paths to different subdirectories of the project, the loggers and the values read from configuration files. (Plus at the moment, two default values that should move to some other place).
None of these values is meant to be changed after it has been set by the main script, what calls settings.init() and then corrects some of them depending on the command-line options. Once this is done, these values can be considered actually as constants (they are not really constants as they are setup and corrected, so no UPPERCASE naming).
tests/conftest.py `` uses the ``settings module the same way mathmaker/cli.py does.
Configuration¶
load_config() handles this and is defined in mathmaker/lib/tools/__init__.py. It works the same way for any of the *.yaml files. It first loads the default values from mathmaker/settings/default/filename.yaml. Then it updates any value found redefined in any of these files: /etc/mathmaker/filename.yaml, ~/.config/mathmaker/filename.yaml and mathmaker/settings/dev/filename.yaml. Any missing file is skipped (except the first one: the default settings are part of the code, are shipped with it and must be present).
An extended dict class is used to deal easier with dicts created from yaml files. See in mathmaker/lib/tools/__init__.py.
The daemon¶
It’s a daemonized web server that allows to communicate with mathmaker through http requests. See http server (mathmakerd).
The database¶
The aim of the database is to avoid having to create a lot of randomly values and store them in lists or dicts everytime we need something.
It is considered as a source among others.
The sources¶
They concern as well numbers as words or letters or anything one can think of.
Note
Old style sheets don’t use sources.
When random numbers are required, most of the time, we don’t need complete random. For instance if we want a pair of integers for the multiplication tables between 2 and 9, we don’t want to ask the same question twice in a row.
The sources manage this randomness. Anytime we need to use a source, we can use its next() method to get the next random data, without worrying in the same time whether it’s the same as the previous one or not.
So we have sources for names, for words having a limited number of letters, for different kinds of numbers but also for mini-problems wordings.
So far, there are two kinds of sources: the ones that are provided by the database, and the ones that are provided by the function generate_values(). They both reside in mathmaker/lib/tools/database.py.
All sources are initialized in mathmaker/lib/shared.py. There you can see which one has its values provided by the database, which are the other ones.
The database provides an easy way to ensure the next value will be different from the last one: we simply “stamp” each drawn value and the next time we draw a value among the yet unstamped ones. When they’re all stamped, we reset all stamps and redraw. There’s a tiny possibility to draw two times in a row the same value, so far, but it’s so tiny we can safely ignore it. (This could be improved later). The values drawn from generate_values() are so different the ones from the others that it’s very unlikely to draw the same ones two times in a row.
The real and the fake translation files¶
mathmaker/locale/mathmaker.pot is a real translation file.
The other mathmaker/locale/*.pot files are “fake” ones. They are used to get random words in a specific language, but the words do not need to be the exact translation from a source language.
For instance, w4l.pot contains words of four different letters. It wouldn’t make sense to translate the english word “BEAN” into a word of the same meaning AND having exactly four different letters, in another language. This wouldn’t work for french, for instance. In general this would only work for rare exceptions (like “HALF” can be translated to “DEMI” in french).
The same applies to feminine_names.pot and masculine_names.pot. These files are used to get random names, but we don’t need to translate them.
So, the entries in these “fake” translation files are only labeled entries, with nothing to translate.
A translator only needs to provide a number of entries (at least 10) in each of these files. No matter how many, no matter which msgid do they match. So: in masculine_names.po are several masculine names required, in feminine_names.po are several feminine names required and in w4l.po are several words of four unique letters required. Each time, at least 10, and then, the more the better.
The sheets, exercises and questions¶
There is still a bunch of “old-style” written sheets, that were not generated from yaml documents. I won’t describe them thoroughly. They will disappear in the future, when they’re replaced by their yaml counterparts. They are kept in lib/old_style_sheet/, so far. They use the classes S_Structure and S_Generic. S_Structure handles the layout of the sheet depending on the SHEET_LAYOUT dict you can find at the top of any sheet module.
Another bunch have been written in XML. They will disappear. So far, mathmaker can read the sheets data from a xml or a yaml document, but the xml format will be dropped in 0.7.2, so don’t bother with it now.
So, all new sheets are stored in yaml files (under data/frameworks/theme/subtheme.yaml, for instance data/frameworks/algebra/expand.yaml).
They are handled by sheet.py, exercise.py and question.py in lib/document/frames/.
The core¶
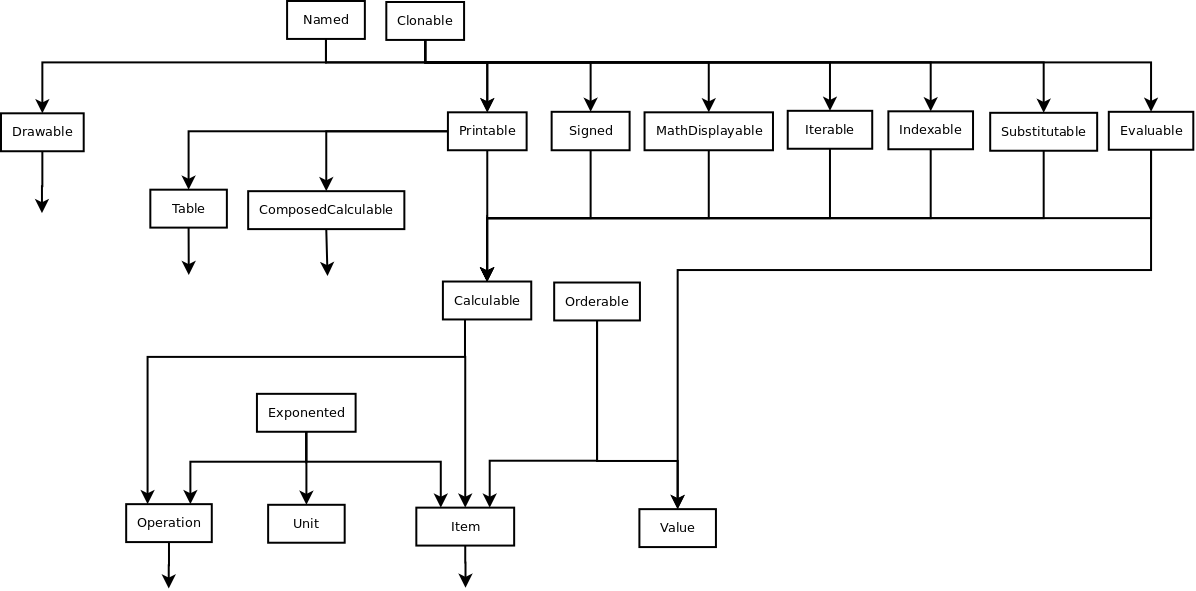
Diagram¶
You can check the 0.6 version (i.e. from doxygen) of the top of the core diagram, though it will be somewhat changed later, it still can be used as reference for some time.
Unfinished draft of future plans:

What can be done?¶
See the tickets on sourceforge and especially the ones for the 1.0 version.
mathmaker package¶
Subpackages¶
- mathmaker.lib package
- Subpackages
- mathmaker.lib.constants package
- mathmaker.lib.core package
- mathmaker.lib.document package
- Subpackages
- mathmaker.lib.document.content package
- Subpackages
- mathmaker.lib.document.content.algebra package
- mathmaker.lib.document.content.calculation package
- Submodules
- mathmaker.lib.document.content.calculation.addi_direct module
- mathmaker.lib.document.content.calculation.addi_hole module
- mathmaker.lib.document.content.calculation.decimal_numerals module
- mathmaker.lib.document.content.calculation.digitplace_direct module
- mathmaker.lib.document.content.calculation.digitplace_numberof module
- mathmaker.lib.document.content.calculation.digitplace_reversed module
- mathmaker.lib.document.content.calculation.divi_direct module
- mathmaker.lib.document.content.calculation.divi_euclidean module
- mathmaker.lib.document.content.calculation.divisibility_rule module
- mathmaker.lib.document.content.calculation.divisibility_vocabulary module
- mathmaker.lib.document.content.calculation.fraction_of_a_linesegment module
- mathmaker.lib.document.content.calculation.fraction_of_a_rectangle module
- mathmaker.lib.document.content.calculation.fraction_simplification module
- mathmaker.lib.document.content.calculation.mini_pb_proportionality module
- mathmaker.lib.document.content.calculation.mini_pb_time module
- mathmaker.lib.document.content.calculation.multi_clever module
- mathmaker.lib.document.content.calculation.multi_direct module
- mathmaker.lib.document.content.calculation.multi_hole module
- mathmaker.lib.document.content.calculation.multi_reversed module
- mathmaker.lib.document.content.calculation.numeric_expansion module
- mathmaker.lib.document.content.calculation.numeric_factorization module
- mathmaker.lib.document.content.calculation.order_of_operations module
- mathmaker.lib.document.content.calculation.percent_direct module
- mathmaker.lib.document.content.calculation.subtr_direct module
- mathmaker.lib.document.content.calculation.subtr_hole module
- mathmaker.lib.document.content.calculation.units_conversion module
- mathmaker.lib.document.content.calculation.vocabulary_addi module
- mathmaker.lib.document.content.calculation.vocabulary_divi module
- mathmaker.lib.document.content.calculation.vocabulary_multi module
- mathmaker.lib.document.content.calculation.vocabulary_questions module
- mathmaker.lib.document.content.calculation.vocabulary_simple_multiple_of_a_number module
- mathmaker.lib.document.content.calculation.vocabulary_simple_part_of_a_number module
- mathmaker.lib.document.content.calculation.vocabulary_subtr module
- Module contents
- mathmaker.lib.document.content.geometry package
- Submodules
- mathmaker.lib.document.content.geometry.area_rectangle module
- mathmaker.lib.document.content.geometry.area_righttriangle module
- mathmaker.lib.document.content.geometry.intercept_theorem_butterfly module
- mathmaker.lib.document.content.geometry.intercept_theorem_butterfly_formula module
- mathmaker.lib.document.content.geometry.intercept_theorem_converse_butterfly module
- mathmaker.lib.document.content.geometry.intercept_theorem_converse_triangle module
- mathmaker.lib.document.content.geometry.intercept_theorem_triangle module
- mathmaker.lib.document.content.geometry.intercept_theorem_triangle_formula module
- mathmaker.lib.document.content.geometry.perimeter_polygon module
- mathmaker.lib.document.content.geometry.perimeter_rectangle module
- mathmaker.lib.document.content.geometry.perimeter_righttriangle module
- mathmaker.lib.document.content.geometry.rectangle_length_or_width module
- mathmaker.lib.document.content.geometry.trigonometry_calculate_angle module
- mathmaker.lib.document.content.geometry.trigonometry_calculate_length module
- mathmaker.lib.document.content.geometry.trigonometry_formula module
- mathmaker.lib.document.content.geometry.trigonometry_vocabulary module
- mathmaker.lib.document.content.geometry.volume_rightcuboid module
- Module contents
- Submodules
- mathmaker.lib.document.content.component module
- Module contents
- Subpackages
- mathmaker.lib.document.frames package
- mathmaker.lib.document.content package
- Module contents
- Subpackages
- mathmaker.lib.machine package
- mathmaker.lib.old_style_sheet package
- Subpackages
- mathmaker.lib.old_style_sheet.exercise package
- Subpackages
- mathmaker.lib.old_style_sheet.exercise.question package
- Submodules
- mathmaker.lib.old_style_sheet.exercise.question.Q_AlgebraExpressionExpansion module
- mathmaker.lib.old_style_sheet.exercise.question.Q_AlgebraExpressionReduction module
- mathmaker.lib.old_style_sheet.exercise.question.Q_Calculation module
- mathmaker.lib.old_style_sheet.exercise.question.Q_Equation module
- mathmaker.lib.old_style_sheet.exercise.question.Q_Factorization module
- mathmaker.lib.old_style_sheet.exercise.question.Q_RightTriangle module
- mathmaker.lib.old_style_sheet.exercise.question.Q_Structure module
- Module contents
- mathmaker.lib.old_style_sheet.exercise.question package
- Submodules
- mathmaker.lib.old_style_sheet.exercise.X_AlgebraExpressionExpansion module
- mathmaker.lib.old_style_sheet.exercise.X_AlgebraExpressionReduction module
- mathmaker.lib.old_style_sheet.exercise.X_Calculation module
- mathmaker.lib.old_style_sheet.exercise.X_Equation module
- mathmaker.lib.old_style_sheet.exercise.X_Factorization module
- mathmaker.lib.old_style_sheet.exercise.X_RightTriangle module
- mathmaker.lib.old_style_sheet.exercise.X_Structure module
- Module contents
- Subpackages
- mathmaker.lib.old_style_sheet.exercise package
- Submodules
- mathmaker.lib.old_style_sheet.AlgebraBinomialIdentityExpansion module
- mathmaker.lib.old_style_sheet.AlgebraExpressionReduction module
- mathmaker.lib.old_style_sheet.AlgebraFactorization_01 module
- mathmaker.lib.old_style_sheet.AlgebraFactorization_03 module
- mathmaker.lib.old_style_sheet.AlgebraMiniTest0 module
- mathmaker.lib.old_style_sheet.ConverseAndContrapositiveOfPythagoreanTheoremShortTest module
- mathmaker.lib.old_style_sheet.EquationsBasic module
- mathmaker.lib.old_style_sheet.EquationsClassic module
- mathmaker.lib.old_style_sheet.EquationsHarder module
- mathmaker.lib.old_style_sheet.FractionSimplification module
- mathmaker.lib.old_style_sheet.FractionsProductAndQuotient module
- mathmaker.lib.old_style_sheet.FractionsSum module
- mathmaker.lib.old_style_sheet.PythagoreanTheoremShortTest module
- mathmaker.lib.old_style_sheet.S_Structure module
- Module contents
- Subpackages
- mathmaker.lib.tools package
- Subpackages
- Submodules
- mathmaker.lib.tools.database module
- mathmaker.lib.tools.distcode module
- mathmaker.lib.tools.frameworks module
- mathmaker.lib.tools.ignition module
- mathmaker.lib.tools.maths module
- mathmaker.lib.tools.request_handler module
- mathmaker.lib.tools.wording module
- mathmaker.lib.tools.xml module
- Module contents
- Submodules
- mathmaker.lib.shared module
- mathmaker.lib.shared_daemon module
- Module contents
- Subpackages
- mathmaker.settings package